I built a simple NLP classifcation model using New York Times articles quite a while ago (late 2015 I believe) but I thought i’d put a little write-up here. You can find source code and jupyter notebooks in the NYT_article_classication repo. A version of the corpus (fancy term for a collection of text data) generated in 2015 is available to download here.
What are we modelling?
The NYT website publishes articles under lots of different categories (Arts, Politics, Sports, etc.). It would interesting to see how accurately we could classify these articles based on there text.

NYT Article Categories
Do to this we scrape 1010 articles from each of 5 article categories (so 5050 articles in total):
- Arts
- Business
- Obituaries
- Sports
- World
The corpus is split into a train and test set and Bernoulli Naive Bayes classifier is trained on the training data and the holdout set is used to assess accuracy at the end.
How did we get the data?
The data is pulled via the NYT API.
The NYT Article Search API
First thing you have to do is signup and register as a developer. API Keys are assigned by API, so make sure you specify the Article Search API.
Once you have recieved an API key set it as environmntal variable nyt_api_key in your .bash_profile:
export nyt_api_key=<YOUR API KEY>
Even before you register, you can use the NYT’s handy API Console to interactively test your queries: http://developer.nytimes.com/io-docs
The Article Search API is pretty flexible; you can call it with no parameters except for your api-key and it will return (presumably) a list of articles, in reverse chronological order, starting from Sept. 18, 1851. However, it only returns 10 articles per request. And it won’t let you paginate beyond a page parameter of 100 (i.e. you can’t go to page 100000 to retrieve the 1,000,000th oldest Times article). To put it another way, you can only paginate through a maximum of 10,000 results, so you’ll have to facet your search.
A lot more information about the article can be pulled out, but for the classication project we only need the title and body text.
What modelling approach did we take?
For this post we just apply a simple ‘bag-of-words’ and a Bernoulli Naive Bayes classifer. We perform a cross-validation parameter sweep over the smoothing parameter parameter and pick the parameter that optimises mean-accuracy.
Bayes Law
To understand the Naive Bayes algorithm we first need to understand Bayes Law. Bayes Law is easily derived and describes how a conditional probability is related to
assuming . In the formula above:
- (the likelihood of event occurring given is true) is known as the posterior. It is the degree of belief in having accounted for .
- is the prior, what is our initial understanding of the probability of absent any knowledge of .
- is the scaled likelihood, and represents support obervation provides for .
Use in text classification
A single word
Ok, but how does this relate to text classification? Suppose the word “football” appears in an article, this probably adds to the likelihood that the article has been filed under the “Sports” desk, but by how much? Well we can use Bayes Law to tell us
The RHS of the equation we can compute with enough pre-labeled data
-
is just the probability that the word “football” appears in an article under the Sports desk. We can actually get an idea of this by running a
grepon the NYT Sports corpus>> cd nyt_corpus/txt_document/ >> grep -r "football" Sports/ | wc -l 208so
- is the probability that the article under the Sports desk. In our NYT corpus each of the 5 categories has an equal number of articles so .
-
is the probability that any article contains the word “football”. Again, in our NYT corpus we can find this just by using
grep>> grep -r "football" . | wc -l 353so
All together
In other words, an article that contains the word “football” has a 70% probability of being a Sports article.
Multiple words
Now, how do we apply this idea to a text document with lots of words? Well, we can take our entire corpus and count the number of unique words that appear (call it ). Now we can represent each document as a vector of length where each element of the vector inidcates the absense or presnece of a corresponding word. Ie. a corpus comprised of two individual sentences
- A brown cow
- The brown cow jump the moon
Could be represented as the two vectors
We can then calculate the probability that a document represented as a vector belongs to some class is
This is the Benoulli Naive Bayes equation, naive because we “assume” that the probabilities of words are independent. We know this isn’t actually the case, because of the structure of language some words are much more likely to appear in close proximity to each other but it is a useful simplification that provides a quite effective model in some applications like text classification. It is called Benoulli (after the Benoulli distribution) because we are only using a binary flag to inidcate the presence or absense of a word. Another implementation of NB, known as Multinoimal Naive Bayes takes in word counts as vector elements.
We can solve the above equation by taking the log of both side, which will turn our product into a summation and rearranging a little bit
where the quantities and don’t depend on any given document. These can be precomputed/trained on the whole corpus.
An additional improvement
The sklearn Bayes theorem has a parameter alpha. This parameter is an Additive (Laplace/Lidstone) smoothing parameter. In this type of smoothing we replace our estimate of with a slightly more complicated expression. The term is really just a ratio of counts, where is the number of counts in an article belonging to class and is the number of counts of the word in any article (look back at the connection in the single word “football” example for the connection). Now we almost certainly never want this probability to be 0 or 1. There is no word that would be imposible to appear in a text document and we don’t want our model to be too over-zealous given the training data it has been exposed to.
What we need is to introduce some priors that explicitly account for the fact that we expect the possibility that any given word might appear in a document of a class. This is what the alpha parameter does. In affect an attempt to prevent the model from overfitting the training data. The higher the value of alpha the stronger our belief that any word could appear in any class (ie. the more evidence/data/observations we need to change our posterior). The alpha parameter is an variable that we can tune to whatever gives us the best result.
What were the results?
All the modelling code/results are in the notebook nyt_article_clf_modelling.ipynb in the NYT_article_classication repo. I just include a few figures comments here.
Doing a parameter sweep over the smoothing parameter using a 3-fold cv grid search and judging the model with mean-accuracy (accuracy across all the classes averaged over the three cross-validation folds gives us)
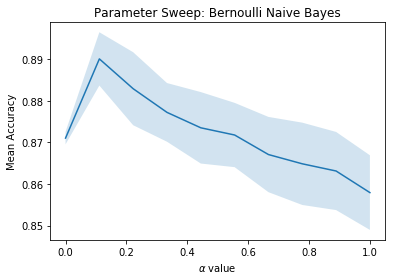
We see a value of alpha=0.13 optimises accuracy in this case.
Scoring on the hold out test set we get an accuracy of 0.94, not too bad for a very simple model! The confusion matrix looks like
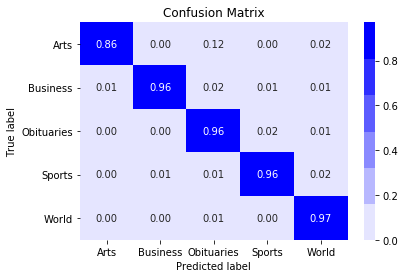
Proportional Confusion Matrix
Interestingly we see that we are classifying Sports and World desks at a > 98% accuracy, however the Arts desk articles are liable to be mislabeled, particularly as either Obituaries or World. This is perhaps not entirely suprising.
We are also able to look at what words contribute most to classifying an Article as a particular desk (see table below). We do this by defining a “discrimination metric” that measures how much predictive power a work has for one class, relative to all the other classes.
Words are then sorted by there absolute value. We use absolute value because words can be discrimating either because of there presence (+) or absense (-).
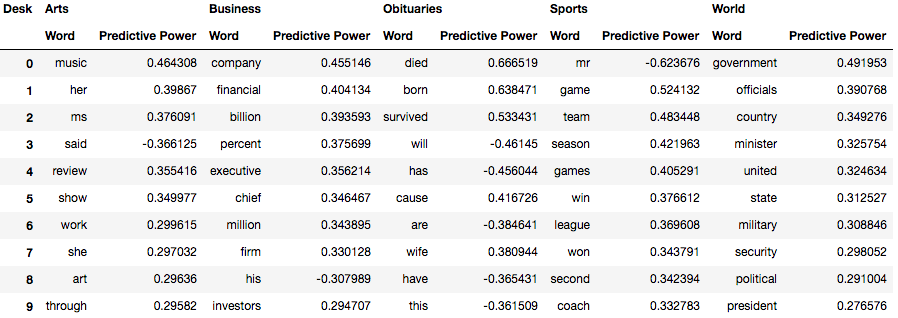
Most Predictive Words
It is worth having a look at a few of these words
- In the Arts desk unsurprisingly music, art, work, review and show all make an appearance. Perhaps a bit more of a suprise are the predictive power of the female pronouns ms, her and she. What seems to be going on here is that the Arts articles are more likely to be about women than the articles coming from other desks. Also the word said has a negative probability (ie. the word said is much more likely to appear in non-Art articles than Art articles)
- The Business is fairly obvious too. Words of commerce like millions, billions, financial, chief, executive, investors are all very predictive of business articles. Interesting the male pronoun him also appears here, ppinting at the male dominated nature of the business articles scraped.
- The Obituaries articles is straightforward life and death, born, survived all appear.
- Interesting the most discrimnating word in the Sports desk is mr. I’d suggest that this is because sportpeople are almost never referred to with an honorific. The rest of the words refer to generic sporting terminology (game, team, season etc.) or to victory (won, win).
- The most discriminating words in the World articles are those that refer to poltics and apparatus of state (government, minister, president, military etc). Interestingly united and state is also strongly discrimating showing the common occurence of the USA in these articles (which is not too suprising given it is a US newspaper and the USA is a dominant actor on the world stage.)
References
- Doing Data Science, Cathy O’Neil \& Rachel Schutt, pg. 98-104, O’Reilly (2014)
- Naive Bayes sklearn docs